{kind=link}
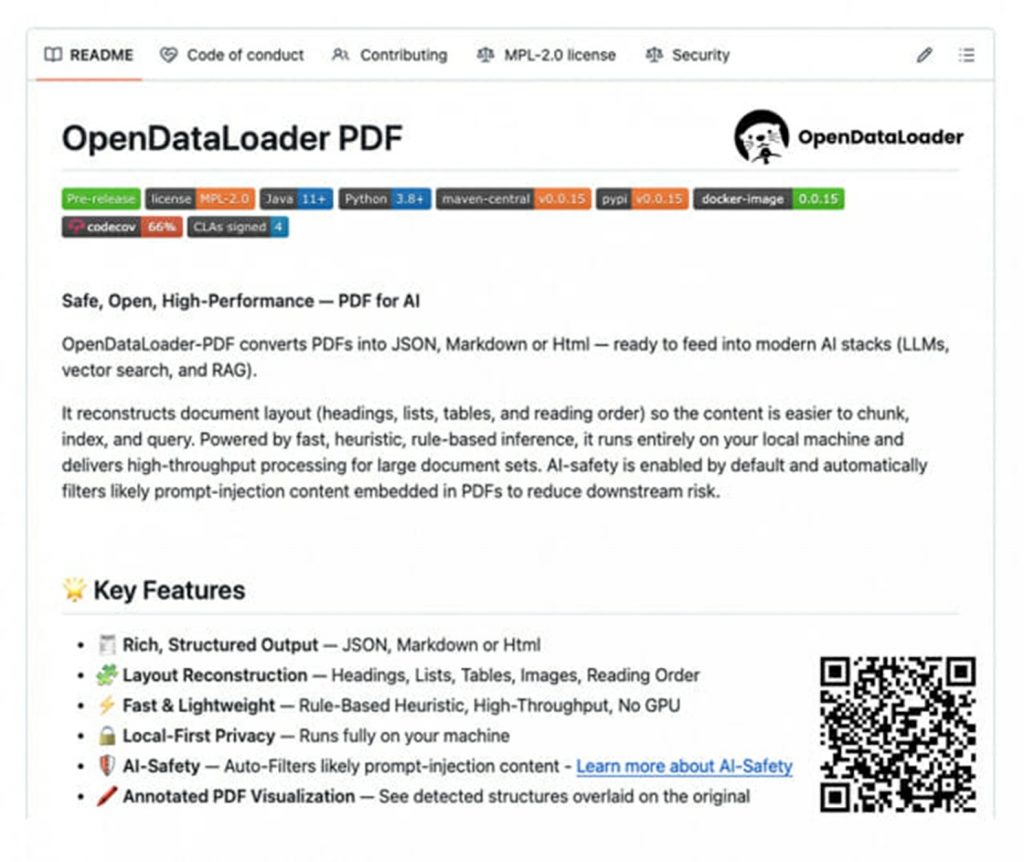
韓国のソフトウエア企業「ハンコム(HANCOM)」が、AIの学習・活用過程で長年指摘されてきたPDF文書データ処理のボトルネック問題を解消する技術を、グローバルオープンソースとして公開した。
韓国メガ・ニュース(MEGA News)のハン・ジョンホ記者の取材によると、ハンコムは、自社の文書処理技術力を基盤に開発したPDFデータ抽出エンジン「オープンデータローダー PDF」のオープンソースプロジェクトを推進する。
最近、Hugging FaceはPDF文書を基にした約4億7500万件規模の大規模データセット「FinePDFs」を公開し、これを活用しようとする企業の動きも本格化している。
PDFは世界的にAI学習に最も広く使われている文書フォーマットだが、その内部構造が複雑で、学習用データの抽出が容易ではない。このため「データの牢獄」とも呼ばれ、AI開発の過程で大きな制約となってきた。
こうした問題を解決するため、ハンコムは今年7月、PDF技術専門企業であるデュアルラボと業務協約(MOU)を締結した。今回のオープンソースプロジェクトは、このMOUの初の成果物だ。
両社はオープンソースベースのPDFデータローダーを共同開発し、AIエコシステムの拡大を目指しており、今回の技術公開を通じてその本格的な普及に乗り出す。
共同開発された「オープンデータローダー PDF」は、PDF文書内のテキスト・表・画像・レイアウト情報を高い精度と高速なパフォーマンスで抽出し、AI学習に即時活用できる構造化データへと変換する。
特に、既存の競合オープンソース技術よりも優れた性能を証明している。公式サイトで公開されたベンチマークテストによると、人間の読書順序を評価する指標であるNIDにおいて、他の技術と比較して85%という高い数値を記録するなど、さまざまなテストで優れた成績を収めている。
また、金融機関や公共機関など、機密データを扱う環境でもネットワーク接続なしで完全にオフラインで動作するため、データ流出や外部アップロードによる情報漏洩リスクを根本的に遮断する。このようなオフラインベースのセキュリティ性能は、企業や機関単位での活用において重要な技術的利点となる。
さらに、近年のAI産業で大きな話題となっている学習データの安全性問題に対応するための戦略も盛り込まれている。「オープンデータローダー PDF」は、悪意あるコンテンツの挿入によるプロンプトインジェクションなどのセキュリティ脅威を自動で検出・遮断する機能も追加提供される。
これにより、AI学習データの安全性と信頼性を同時に確保し、より安全なAIモデル学習環境の構築に貢献する方針だ。
ハンコムは今回のオープンソース公開を通じて、単なる技術共有にとどまらず、AIエコシステム全体のオープンソース普及と技術高度化を推進している。これに向けて、ChatGPT、Gemini、LangChainなど主要AIフレームワークとの連携・互換性を強化し、GitHubを通じたグローバル開発者コミュニティとの協力を継続する。
ハンコムのチョン・ジファン最高技術責任者(CTO)は「AI転換の時代において、オープンソースはもはや選択肢ではなく、企業と社会全体の革新と競争力確保のための必須戦略だ。今回のオープンデータローダー PDFの核心技術公開を通じて、世界中の開発者から認められ、協力を通じてPDFデータ抽出技術をさらに進化させ、グローバル最高水準のAIデータ抽出技術を完成させたい」と語った。
(c)KOREA WAVE