{kind=link}
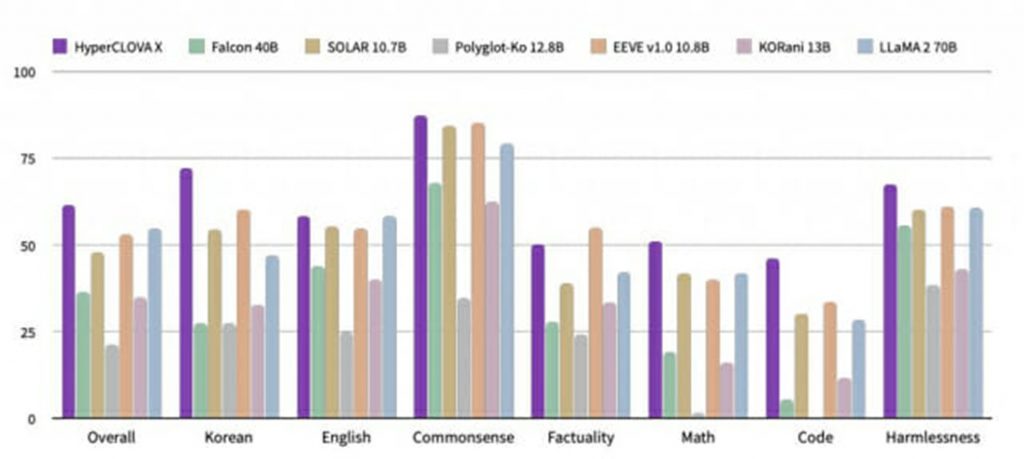
韓国ネット大手「ネイバー」は4日、同社独自の生成AI(人工知能)「ハイパークローバーX」の性能をオープンソースや閉鎖型モデルと比較した結果を公開した。米メタのオープンソースモデル「LLaMA(ラマ)」やオープンAIの閉鎖型モデルGPTより翻訳、推論、数学、一般常識などで高い性能を記録したという。6つ以上のベンチマーク点数を平均化した方式を活用し、結果の信頼性も高いと評価されている。
ベンチマークテスト分野は韓国語をはじめとする外国語、推論、一般常識、数学、コーディングなどだ。
ネイバーはハイパークローバーXが韓国語だけでなく英語、中国語など多言語部門で上位圏を記録したという立場だ。研究チームは、自社の巨大言語モデル(LLM)が韓国語と英語情報を活用して第3の言語で推論する能力を他社のモデルと比較した。このモデルは日本語とアラビア語、ヒンディー語、ベトナム語をはじめとするアジア各国の言語能力部門でオープンソースモデルを含め、レポートで選定した9つのモデルの中で最も高い点数を獲得した。中国語部門では同じ閉鎖型モデルの中で2位を記録した。
機械翻訳の評価も同じだ。韓国語を日本語に、日本語を韓国語に翻訳する能力は、実際にサービス中の翻訳モデルなどレポートで選定した10のモデルの中で1位を記録した。英語を韓国語に翻訳する精度も同じ10モデルの中で最も高い点数を獲得した。
ネイバーは自社のLLMがオープンソースモデルだけでなく、オープンAIのGPT-3.5やGPT-4などの閉鎖型モデルより特定部門で性能を上回ったとしている。
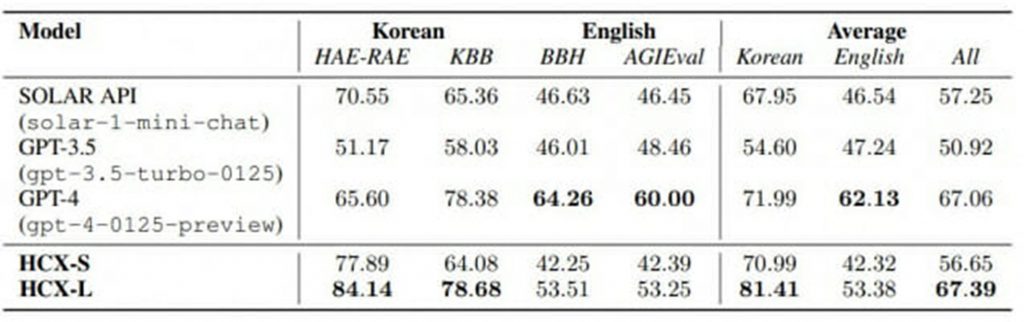
韓国語能力部門で14モデルのうち最も高い点数を記録した。英語能力分野では閉鎖型モデルの中で2番目に高い点数をとった。1位はオープンAIのGPT-4だった。
◇ベンチマークの多様化
ネイバーは、性能評価の信頼性は高いという立場だ。ネイバー関係者は「さまざまなベンチマークデータセットを基に点数を平均化する方式で総合点数を導き出した」と説明した。

例えば、ハイパークローバーXとオープンソースモデルの一般常識性能を比較する場合、ARCやCSQA、Hellaswag、Winogrande、PIQAの5つのベンチマーク点数を平均化して総合点数を導出した。韓国語能力測定を比較するため、韓国版AI試験として知られているKMMLUをはじめ、世界的なAI言語理解能力評価であるMMLU、マイクロソフトのAI性能評価AGIevalなど6つのベンチマーク点数を総合した。
関係者は「最近、特定のリーダーボードで順位を高めようと、評価データをモデル学習に活用し、ベンチマークテストの点数を上げる事例がある。これを勘案して複数のベンチマークテストの平均値で客観性を保った」と説明した。
一定水準以上の競争力を持つ韓国語と英語モデルを比較群に選定したのも信頼性を高めるための方法だ。ネイバークラウドでリーダーを務めるユ・ガンミン氏は「ハイパークローバーXの多言語推論、機械翻訳能力を測定した実験は、地域または文化圏特化目的で開発したAIが該当国言語の他にもさまざまな言語で一定水準以上の能力を備えていることを実証した」と説明した。
◇「モデルの脆弱性を補完」
ネイバー研究陣は、LLM学習過程についても説明した。報告書によると、ハイパークローバーXの事前学習データは大部分が韓国語、英語、コードデータで構成されている。このうち、過度に短いか反復的な低品質文書はデータセットから除外された。個人情報が入っているデータも削除された。また、整列学習を通じて使用者の意図と指示をよりよく理解できるようにモデルを高度化した。
同社はハイパークローバーXが偏向した結果を生成しないような措置を取ったとしている。ネイバー側は「社会的課題と偏向、不法な行動などに敏感であったり、危険なテーマを設定したりして質のデータを収集した。これを基にモデルの脆弱性を補完した」と話した。今後、ハイパークローバーX倫理原則に基づき、嫌悪、偏向、著作権侵害、個人情報などと関連したコンテンツの生成頻度をさらに減らすとしている。
ネイバークラウドハイパースケールAIのソン・ナクホ技術総括は「ハイパークローバーXは韓国に特化した知識だけでなくプログラミングと数学的推論、多言語能力、安全性まで確保した。今後、多様な国・地域に特化した超大規模AIを作ることにも積極的に乗り出す」と話した。
(c)KOREA WAVE